ZYBOでOPC UAサーバーを動かしてみた
はじめに
OPC UAを扱うためのOSSライブラリにopen62541があります。Linuxボードで動かすだけならFreeOpcUa/python-opcuaあたりも使えますが、個人が組み込みソフトウェアにOPC UAサーバーを載せたいと思ったときの選択肢はほぼopen62541一択です。
open62541の組み込み実装はv1.3までで最新の機能は使えませんが、OPC FOUNDATIONの認証を取得したのはv1.0なので、個人で遊ぶ分には仕様面で困ることはありません。
難点は、open62541を組み込みソフトウェアで動かしている実例がSTM32とESP32くらいしかないことです。導入方法はドキュメントに記述されていますが、ライブラリの実装が古くなっているものや詳細な必要環境は掲載されていません。
そこでこの記事では、組み込みでOPC UAサーバーを立てて遊びたい方が同じところで躓かないように、ZYBOというXilinx社製CPUの評価ボードでopen62541を動かすためにやったことをまとめておきます。
開発環境
- Xilinx SDK 2019.1
- Vivado 2019.1
- Open62541 v1.28
- ZYBO(Zynq Z-7010 + Realtek RTL8211E-VL PHY)
- Ubunrtu20.04 (WSL2)
open62541の導入方法
自分はV1.28のソースコードを落としてきてWSL環境でビルド手順を通しました。ソースコードをクローンしたディレクトリで下記コマンドを順に実行すればopen62541.cとopen62541.hというファイルが生成されます。makeの途中でエラーが発生するのは無視してください。
mkdir build_freeRTOS cd build_freeRTOS cmake -DUA_ARCHITECTURE=freertosLWIP -DUA_ENABLE_AMALGAMATION=ON ../ make
生成されたopen62541.cとopen62541.hを自分のプロジェクトにインポートすれば使えるようになります。
Xilinx SDKでプロジェクトを作成する方法
Xilinx SDK 2019.1はサンプルプロジェクトでFreeRTOS+lwipの入ったプロジェクトを生成してくれます。open62541を組み込み環境で使うにはFreeRTOS+lwipが必要なのでサンプルプロジェクトを改造して作成しましょう。
ちなみに記事中でHardware Platformに指定しているsimplepsははwatakeさんの記事(ZYBO (Zynq) 初心者ガイド (1) 開発環境の準備 - Qiita)を参考に作成したものです。
Xilinx SDKの新規プロジェクト作成から、OSにfreertos10_xilinxを選びnextをクリックします。
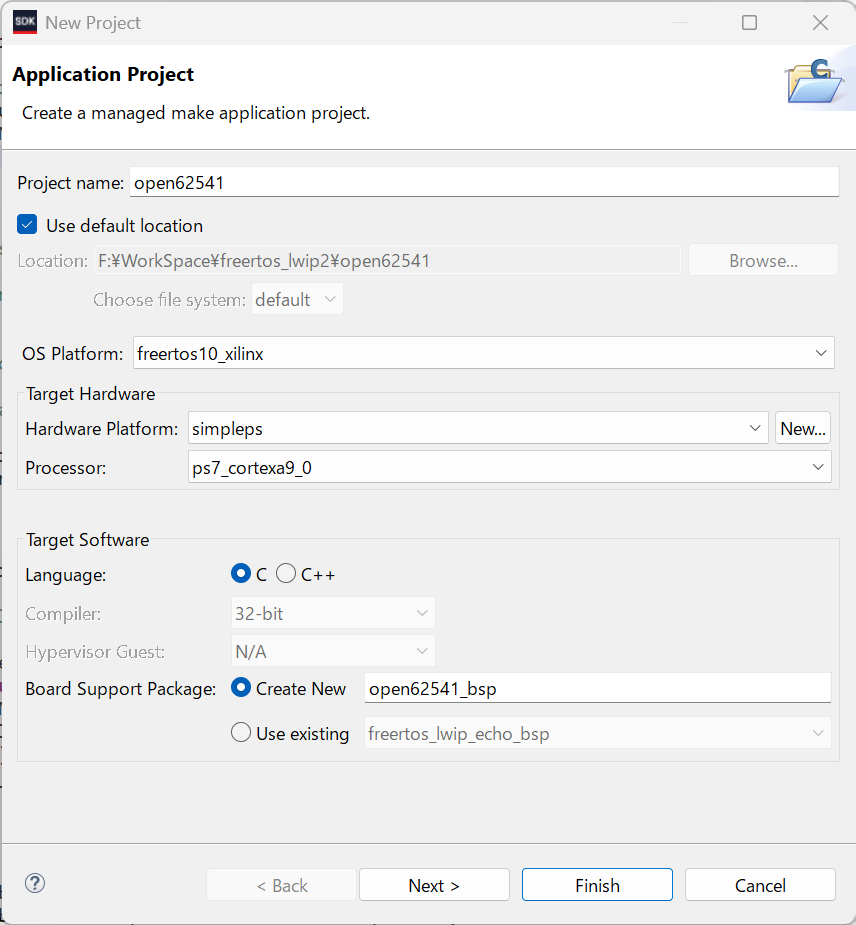
テンプレート選択でlwipのechoサーバーを選択します。

これだけでZYBOがtelnetで接続してきた端末の送信データをそのままオウム返しするEchoサーバが立ち上がりません。
lwipのPHYドライバを騙す
サンプルプロジェクトのelfファイルをZYBOに書き込んでteratermなどで接続すると、下記のようにPhyセットアップにコケているログが表示されます。
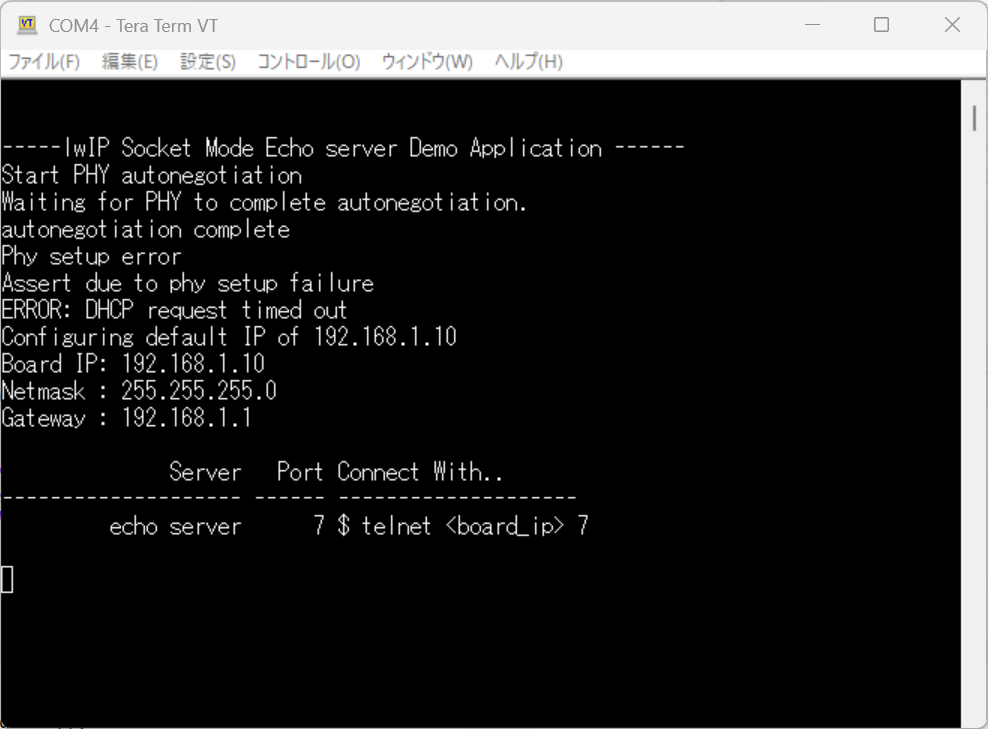
残念ながらXilinx SDKが自動生成してくれるlwipはMarvell PHYしかサポートしていないようです。そのため、Realtek PHYを積んでいるZYBOはAuto Negotiationに失敗していつまでもネットに接続できません。
https://support.xilinx.com/s/article/63495?language=en_US
といってもコケているのはAuto Negotiationの最後、通信速度を決める段階だけです。本当はdatasheetを見て修正すべきですが、とっととOPC UAサーバーを立てたかったので無理やりxemacpsif_physpeed.cを下記のコードに書き換えて動作させました。
static u32_t get_Realtek_phy_speed(XEmacPs *xemacpsp, u32_t phy_addr) { ... return 1000; /* ここより下でコけるので、固定通信速度で動かす */ XEmacPs_PhyRead(xemacpsp, phy_addr,IEEE_SPECIFIC_STATUS_REG, &status_speed); if (status_speed & 0x400) { temp_speed = status_speed & IEEE_SPEED_MASK; if (temp_speed == IEEE_SPEED_1000) return 1000; else if(temp_speed == IEEE_SPEED_100) return 100; else return 10; } return XST_FAILURE; }
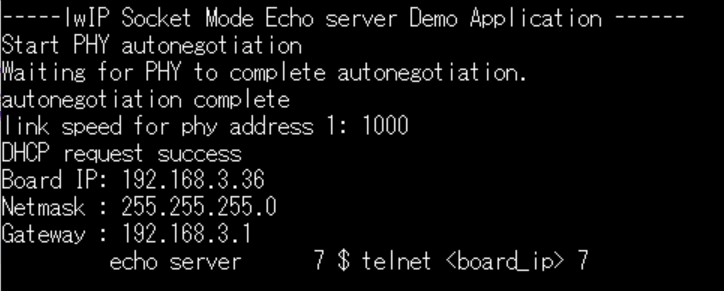
これで端末に指定されるIPアドレスにtelnet接続すると、Echoサーバーとして動作している様子が確認できます。
open62541を動かすための設定。
前述の工程で作ったopen62541をインポートしてください。ビルドが通らなくなるので通すための手順を載せます。
まずlwipopts.hに下記defineを追記してください。
#define LWIP_COMPAT_SOCKETS 0 // Don't do name define-transformation in networking function names. #define LWIP_SOCKET 1 // Enable Socket API (normally already set) #define LWIP_DNS 1 // enable the lwip_getaddrinfo function, struct addrinfo and more. #define SO_REUSE 1 // Allows to set the socket as reusable #define LWIP_TIMEVAL_PRIVATE 0 // This is optional. Set this flag if you get a compilation error about redefinition of struct timeval
次にFreeRTOSConfig.hのdefineを下記のように修正します。
#define configCHECK_FOR_STACK_OVERFLOW 1 #define configUSE_MALLOC_FAILED_HOOK 1 #define configTOTAL_HEAP_SIZE ( ( size_t ) ( 131070) )
次にプロジェクトに下記シンボルを追加してください。
UA_ARCHITECTURE_FREERTOSLWIP OPEN62541_FEERTOS_USE_OWN_MEM
最後にheap_4.cに下記コードを追加してください。
void *pvPortCalloc(size_t count, size_t size) { void *p; /* allocate 'count' objects of size 'size' */ p = pvPortMalloc(count * size); if (p) { /* zero the memory */ memset(p, 0, count * size); } return p; } void *pvPortRealloc(void *mem, size_t newsize) { if (newsize == 0) { vPortFree(mem); return NULL; } void *p; p = pvPortMalloc(newsize); if (p) { /* zero the memory */ if (mem != NULL) { memcpy(p, mem, newsize); vPortFree(mem); } } return p; }
これでビルドが通るようになります。
OPC UAサーバータスクを書いて立ち上げる。
ドキュメントと一か所だけ異なり、UA_ServerConfig_setMinimal関数の代わりにUA_ServerConfig_setMinimalCustomBuffer関数を使っています。恐らくドキュメントが書かれた頃と定義が変わったものと思われます。
static void opcua_thread(void *arg){ //The default 64KB of memory for sending and receicing buffer caused problems to many users. With the code below, they are reduced to ~16KB UA_UInt32 sendBufferSize = 16000; //64 KB was too much for my platform UA_UInt32 recvBufferSize = 16000; //64 KB was too much for my platform UA_UInt16 portNumber = 4840; UA_Server* mUaServer = UA_Server_new(); UA_ServerConfig *uaServerConfig = UA_Server_getConfig(mUaServer); UA_ServerConfig_setMinimalCustomBuffer(uaServerConfig, portNumber, 0, sendBufferSize, recvBufferSize); //VERY IMPORTANT: Set the hostname with your IP before starting the server UA_ServerConfig_setCustomHostname(uaServerConfig, UA_STRING("192.168.0.102")); //The rest is the same as the example UA_Boolean running = true; // add a variable node to the adresspace UA_VariableAttributes attr = UA_VariableAttributes_default; UA_Int32 myInteger = 42; UA_Variant_setScalarCopy(&attr.value, &myInteger, &UA_TYPES[UA_TYPES_INT32]); attr.description = UA_LOCALIZEDTEXT_ALLOC("en-US","the answer"); attr.displayName = UA_LOCALIZEDTEXT_ALLOC("en-US","the answer"); UA_NodeId myIntegerNodeId = UA_NODEID_STRING_ALLOC(1, "the.answer"); UA_QualifiedName myIntegerName = UA_QUALIFIEDNAME_ALLOC(1, "the answer"); UA_NodeId parentNodeId = UA_NODEID_NUMERIC(0, UA_NS0ID_OBJECTSFOLDER); UA_NodeId parentReferenceNodeId = UA_NODEID_NUMERIC(0, UA_NS0ID_ORGANIZES); UA_Server_addVariableNode(mUaServer, myIntegerNodeId, parentNodeId, parentReferenceNodeId, myIntegerName, UA_NODEID_NULL, attr, NULL, NULL); /* allocations on the heap need to be freed */ UA_VariableAttributes_clear(&attr); UA_NodeId_clear(&myIntegerNodeId); UA_QualifiedName_clear(&myIntegerName); UA_StatusCode retval = UA_Server_run(mUaServer, &running); UA_Server_delete(mUaServer); }
main_thread関数の末尾に下記を追記する。
sys_thread_new("opcua_thread", opcua_thread, NULL, 8000, 8);
ビルド&OPC UAサーバーの動作確認!
以上でZYBOからOPC UAサーバーを動かすためにやったことは終わりです。試しに適当なクライアントから自分の環境のエンドポイント"opc.tcp://192.168.3.36:4840"にアクセスすると無事アドレススペースを公開してくれていることが確認できます。
おしゃれに紙を並べたくて2
要約
前回は画像を並べるところまでやりました。

今回はおしゃれ画角で画像を保存するところまでやります。
ソースコード全文。
挨拶
こんにちはたもったです。
今回の開発で初めてjupyter notebookを使ってみたのですが便利さにびっくりしました。Pythonはjupyter notebookで開発するように作られた言語だった…
ただ、僕の開発の仕方が悪かったのか、まとめる段階で不整合が出てきて大変でした。Pythonみたいな高級言語を使うときは変に実行速度なんか意識せずにこまめにアウトプット→参照を繰り返した方が開発時間が短縮できて相性が良さそうですね。
本文
PDFを画像にする前編と画像に画角をつけておしゃれにする後編に分けます。今回は後編です。
前回に引き続き、下の流れで画像を生成します。
PDFの各ページを画像に変換する
各ページ画像に影を付ける
影付きの画像を縦横並べる
縦横並べた画像を斜めから撮影しておしゃれ画像にする。 👈今ここ
前回はmakeImageFromPdf.pyの説明でした。 今回はmakeTileImage.pyの説明です。
4.各ページ画像に影を付ける
OpenGLを使います。
本当は自前でカメラビューっぽく見えるように画像の射影変換をすればよいのです。よいのですが僕には難しかったのでOpenGLのパワーを使っていきたいと思います。
それまでの処理をPythonでやっていたのでここもPyOpenGLを使っていきます。
といっても人様のコードを使いまくっているのであまり説明するところはありません。
テクスチャ作り
画像パスを指定してテクスチャを生成します。
def img2tex(img_path):
img = Image.open(img_path)
img = img.convert('RGBA')
img_data = img.tobytes()
tex = glGenTextures(1)
glBindTexture(GL_TEXTURE_2D, tex)
glTexImage2D(
GL_TEXTURE_2D, #target
0, #level
GL_RGBA, #internalformat
img.size[0], img.size[1], #width, height
0, #border
GL_RGBA, #format
GL_UNSIGNED_BYTE, #type
img_data #pixels
)
return tex
画角の設定
gluLookAtで画角を決めています。
def resizeA(w, h):
glViewport(0, 0, w, h)
glLoadIdentity()
gluPerspective(
1.0, #fovy
1.0, #aspect
0.0, 10.0 #zNear, zFar
)
glRotated(40.0, 0.0, 0.0, 1.0)
# 画角を編集したい場合はここをいじります
gluLookAt(
-7.0, -11.0, 16.0, #eye
0.4, 0.4, 0.0, #center
0.0, 1.0, 0.0 #up
)
画像の保存
マウスの左クリックで画像を保存します。
def mouse(button, state, x, y):
if button == GLUT_LEFT_BUTTON:
glReadBuffer(GL_FRONT)
buf = glReadPixels(
0 ,0, #x, y
1000, 1000, #width, height
GL_RGBA, #format
GL_UNSIGNED_BYTE, #type
)
img = Image.frombuffer('RGBA', (1000, 1000), buf)
img.save('OshaTile.png')
画像を保存すると、

これで皆さんも簡単におしゃ紙並べ画像が作れます。
HPのヘッダにするもよし、自分の論文を強そうに表示するもよし。自由気ままなあなたのおしゃ紙並べライフの始まりです。
僕はこれからこのスクリプトの使い道を考えていきたいと思います。
終わり
自分は昔OpenGLを学校の課題や研究室で触ったことがあるはずなのですが、全く覚えていなくて表示設定などえらく手間取りました。
そんな忘れん坊のあなたも初めてOpenGLを触るあなたも、手抜きOpenGLがおすすめです。
おしゃれに紙を並べたくて
要約
↓こういうのを作るスクリプト作りました。
挨拶
こんにちはたもったです。実に2か月ぶりの更新です。
時が流れるのは早いもので、ブログ開設当初はこれからビシビシ記事を上げていくぞと思っていたのに、気づけばAPEXを始めたりボードゲームアリーナにはまったりしてありえん時間が経っていました。誰かAPEXの勝ち方を教えてください。
本文
先日ヒカテクさん(http://hikatech.com)と話していて、紙をおしゃれに並べたいねという話になりました。これだけ聞くとなんのこっちゃという話なので下の画像をご覧ください。


上の画像のように、紙を縦横綺麗に並べて斜め視点から撮影するとグッとおしゃれになります。
引用元はビズメイト株式会社様と有限会社クローバー様のサイトです。両社とも僕とは全く関係ありませんが、素晴らしい並べっぷりでしたので引用させていただきました。
www.bizmates.jp
というわけで皆さんも自分の文書をおしゃれに並べてみたくなってきましたね。
本記事はそんなおしゃれ紙並べ画像を自動で生成するスクリプトの実装説明です。
ソースコード全文はこちら。
環境構築
OS:Windows10
使用言語:Python3
モジュール:
PIL
PyOpenGL
FreeGLUT
pdf2image
コード解説
PDFを画像にする前編と画像に画角をつけておしゃれにする後編に分けます。今回は前編です。
今回の実装では下の流れで画像を生成します。
PDFの各ページを画像に変換する
各ページ画像に影を付ける
影付きの画像を縦横並べる
縦横並べた画像を斜めから撮影しておしゃれ画像にする。
1.PDFの各ページを画像に変換する
in_pdfというフォルダから任意のPDFを拾ってきてout_imgというフォルダにパコパコ保存していきます。
もちろんin_pdfの中にPDFファイルが入っていないと動きません。out_imgはなければ自動で生成してくれます。
pdf_dir = pathlib.Path('in_pdf')
if not pdf_dir.exists():
pdf_dir.mkdir()
pdf_file = pathlib.Path('in_pdf/' + pdf)
img_dir = pathlib.Path('out_img')
if not img_dir.exists():
img_dir.mkdir()
# PDFを画像に変換
base = pdf_file.stem
images = pdf2image.convert_from_path(pdf_file, grayscale=True, size=1800)
for index, image in enumerate(images):
image.save(img_dir/pathlib.Path(base + '-{}.png'.format(index + 1)), 'png')

2.各ページ画像に影を付ける
画像を並べた時にリアリティを出すため、画像に影を付けました。makeShadowって調べたら出てきた関数を利用させてもらっています。
画像の背景の色味と影の色味を合わせる部分を足したのですが、そこがむちゃくちゃ遅いです。誰か改善して。
def makeShadow(image, iterations, border, offset, backgroundColour, shadowColour):
# image: base image to give a drop shadow
# iterations: number of times to apply the blur filter to the shadow
# border: border to give the image to leave space for the shadow
# offset: offset of the shadow as [x,y]
# backgroundCOlour: colour of the background
# shadowColour: colour of the drop shadow
#Calculate the size of the shadow's image
fullWidth = image.size[0] + abs(offset[0]) + 2*border
fullHeight = image.size[1] + abs(offset[1]) + 2*border
#Create the shadow's image. Match the parent image's mode.
shadow = Image.new("L", (fullWidth, fullHeight), backgroundColour)
print('\rSaving...make Shadow Image',end='')
# Place the shadow, with the required offset
shadowLeft = border + max(offset[0], 0) #if <0, push the rest of the image right
shadowTop = border + max(offset[1], 0) #if <0, push the rest of the image down
#Paste in the constant colour
shadow.paste(shadowColour,
[shadowLeft, shadowTop,
shadowLeft + image.size[0],
shadowTop + image.size[1] ])
# Apply the BLUR filter repeatedly
for i in range(iterations):
shadow = shadow.filter(ImageFilter.BLUR)
print('\rSaving...ImageFilter.BLUR ' + str(i) + ' / ' + str(iterations),end='')
# ここだけ追加。元のままだと影色と背景色が上手くなじまなかったのでshadowの色みをいじった。ココが遅い。
if shadow.mode != "RGB":
shadow=shadow.convert("RGB")
w,h = shadow.size
print('\rSaving...Set color...\033[K',end='')
for x in range(w):
for y in range(h):
r,g,b=shadow.getpixel((x,y))
# ここで色味いじり中、白色と設定したい背景色の差分を引くので注意
shadow.putpixel((x,y), (r-77, g-40, b-14))
print('\rSaving...Set color... ' + str(x) + ' / ' + str(w),end='')
# Paste the original image on top of the shadow
imgLeft = border - min(offset[0], 0) #if the shadow offset was <0, push right
imgTop = border - min(offset[1], 0) #if the shadow offset was <0, push down
shadow.paste(image, (imgLeft, imgTop))
return shadow

3.影付きの画像を縦横並べる
これは2次元リストになっている画像群を縦横良い感じに並べる関数があるのでそれを利用しました。
def convert_1d_to_2d(l, cols):
return [l[i:i + cols] for i in range(0, len(l), cols)]
# 2次元リストの画像から
def concat_tile(im_list_2d):
return cv2.vconcat([cv2.hconcat(im_list_h) for im_list_h in im_list_2d])
def makeTileImage(base, images):
imgs = []
for index, image in enumerate(images):
img = cv2.imread('out_img/shadow/' + base + '_shadow-{}.png'.format(index + 1))
imgs.append(img)
result = convert_1d_to_2d(imgs, 6)
im_tile = concat_tile(result)
今回はここまでです。
Springer Nature社の無料公開教科書をかき集めて2
[要約]
先日書いたコードだとSpringer Nature社の無料公開教科書全てをかき集めることができませんでした。反省。
[本文]
もったです。
先日下の記事を書きまして、思いのほかいろんな方に動かしてもらえました。触ってくださった方々、ありがとうございます。
Springer Nature社の無料公開教科書をかき集めて - もったかぶった
github.com
ただ教科書のタイトルに重複があることを見落としていまして、
先日書いたコードだと重複タイトルを無視して上書きしてしまう致命的な罠がありました。
生成したファイル数を数えればすぐに分かることなのですが、作った当初は万能感に包まれていて全く気付きませんでした。ご指摘くださったフォロワーさんに感謝です。
重複タイトル除けです。
スマートじゃないですが、cumcount()を使って同じタイトルの本をカウントして本のタイトルに追記します。このとき、大部分の本は重複していないので0カウント目はナンバリングしないことにします。
これでpdfファイルを保存するときにファイルの上書きをせずに済みます。
# PDF名に使う本のタイトルを拾ってくる。重複タイトルがあるので2つ目以降をナンバリングする。 df['dummy'] = df.groupby('Book Title').cumcount() df_TITLE = df['Book Title'] + df['dummy'].astype(str).replace('0' , '') df_TITLE = df_TITLE.str.replace('/', '') df_TITLE = df_TITLE.str.replace(':', '') df_TITLE = df_TITLE.str.replace('|', '') df_TITLE = df_TITLE.str.replace('"', '') df_TITLE = df_TITLE.str.replace('?', '') df_TITLE = df_TITLE.str.replace('>', '') df_TITLE = df_TITLE.str.replace('<', '') df_TITLE = df_TITLE.str.replace('\\', '') download_title_list = df_TITLE.values.tolist()
本のカテゴリ分けです。
エクセルファイルをよく見たらタイトルごとに大雑把なカテゴリ分けがされていたので、折角なのでカテゴリ分けを実装していきます。
カテゴリタイトルを取得して、事前にすべてのカテゴリのフォルダを作成します。このとき大量に重複フォルダを作成しますが、tryで囲んで例外を無視していきます。
本当はpython3.2以降ならmakedirs()の引数で重複フォルダを無視することができるのですが、今回はなんとなくこっちで書いてます。興味があれば調べてみてください。
# 折角本のカテゴリ分類があるので分類するためのフォルダを事前に作成する。 df_DIR = df['English Package Name'].astype(str) download_dir_list = df_DIR.values.tolist() for folder in download_dir_list: # Python3.2以降ならもっとスマートな書き方があるけどなんとなくこっち。 try: os.makedirs('./' + folder) except FileExistsError: pass
あとは前回の反省を活かしてコンソールの進捗表示にはダウンロードしたファイル数を表示します。
出力結果はこんな感じになります。
これで今度こそSpringer Nature社の無料公開教科書を"全て"かき集めることができました。やったぜ。
皆さんも今度こそ快適な在宅ライフをお過ごしください。
僕はダウンロードしてきた教科書は読まずにゲームしてます。
Springer Nature社の無料公開教科書をかき集めて
[反省]
前回のコードだと重複しているタイトルに対応してなかったので修正しました。修正箇所の説明はこちら。
Springer Nature社の無料公開教科書をかき集めて2 - もったかぶった
[要約]
PDFをダウンロードするためのWEBスクレイピングの話です。
[本文]
もったです。
突然ですが僕は無料のコンテンツが好きです。
SNSなんかで「〇〇が無償公開される!」とか、「△△が今だけ無料ダウンロード可能!」という情報が流れると乞食根性剥き出しで群がってしまうのが人の常ですね。単純に棚ぼたで高価なものが手に入る喜びもありますが、こういう機会でもないと読まないような本との出会いがあるのも嬉しいところです。
前置きは以上です。
今回はSpringer Nature様が提供してくれている参考書達をせかせかとローカルドライブへ落とすためのスクリプトを組みます。
最近コロナウイルスの影響で様々な教育コンテンツが無償で公開されています。本当にありがとうございます。折角なので感謝の念だけではなく、学べるものは学んでいきましょう。
参考書達をダウンロードするためのソースコードは下記です。
下記のモジュールをimportしています。必要に応じて適宜インストールしてください。
pandas requests xlrd
説明part
仕様としてpdfファイルのタイトルとURLの入ったエクセルファイルを入力とし、ダウンロードしてきたpdfをローカルフォルダへ出力するシステムを考えます。
今回はエクセルファイルを受けるにはpandasを使い、pdfのダウンロードにはrequestsを使っていきます。
エクセルファイルを読み込む。(ここでxlrdをインストールしていないとエラーが出ます)
df = pd.read_excel('./Free+English+textbooks.xlsx')
読み込んだエクセルファイルから必要な列を抜き出す。今回はタイトル列とURL列。
エクセルファイルに書かれているのはpdfファイルの直接の在り処ではなかったので、直接pdfに繋がるようURLをごちゃごちゃ書き換える。
ついでに保存するpdf名用にタイトルも取得する。このときファイル名に使用禁止の文字を全て取り除く。
df = pd.read_excel('./Free+English+textbooks.xlsx') df_URL = df['DOI URL'].astype(str) df_URL = df_URL.str.replace("http://doi.org/","HOGEHOGE") df_URL = df_URL.str.replace('/','%2F') df_URL = df_URL.str.replace('HOGEHOGE','https://link.springer.com/content/pdf/') df_URL = df_URL + '.pdf' download_url_list = df_URL.values.tolist() df_TITLE = df['Book Title'] df_TITLE = df_TITLE.str.replace('/', '') df_TITLE = df_TITLE.str.replace(':', '') df_TITLE = df_TITLE.str.replace('|', '') df_TITLE = df_TITLE.str.replace('"', '') df_TITLE = df_TITLE.str.replace('?', '') df_TITLE = df_TITLE.str.replace('>', '') df_TITLE = df_TITLE.str.replace('<', '') df_TITLE = df_TITLE.str.replace('\\', '') download_title_list = df_TITLE.values.tolist()
ファイル出力部。
読み込んだ2列を片っ端からダウンロードして名付けていく。
ついでに処理経過が分かりやすいようになにをダウンロードしているか、なにがダウンロードし終わったのかコンソールへ出力させる。
for (download_url, download_title) in zip(download_url_list, download_title_list): title = str(download_title) print('DOWNLOADING...: ' + title, end='\r') # 一秒スリープ time.sleep(1) r = requests.get(str(download_url)) print('GET : ' + title) # ファイルの保存 if r.status_code == 200: with open(title + '.pdf', "wb") as f: f.write(r.content) f.close()|<
ファイルのダウンロード部分。
r = requests.get(str(download_url))
ファイル書き込み部分。ダウンロードが上手くいったらさっき取得した本のタイトルでpdfを書きだす。
if r.status_code == 200: with open(title + '.pdf', "wb") as f: f.write(r.content) f.close()|<
以上でエクセルファイルにリストアップされたpdfを自動でダウンロードしてくるwebスクレイピングスクリプトの説明は終わりです。
皆さんも快適な在宅ライフをお過ごしください。